Së pari, dhe më pak e rëndësishmja, “digjitale”, e shkruar me “gj” tingëllon çuditshëm, … pavarsisht vendlindjes. Shqipja shkruhet siç flitet, por dikush, a disa, tek Akademia e Shkencave, kanë vendosur ta ᗪяE𝓙ᵗ𝔰н𝓴𝔯𝓾𝒶𝐉ηe, duke harruar që një gjuhë që nuk flitet, vdes - ndoshta jo shumë ndryshe nga vetë Akademia. Tani që fjalët e ëmbla i thamë, le ta kthejmë vëmendjen tek një tjetër institucion: Biblioteka Kombëtare.
Biblioteka Kombëtare Digjxhitale dhe Fletoret
Një pjesë shumë të vogel të katalogut, kryesisht vepra të vjetra që janë në domain-in publik[1], Biblioteka Kombëtare e ofron nëpërmjet Bibliotekës Kombëtare Dixhitale (BKD), të cilën mund ta gjeni në këtë adresë: bibliotekadigjitale.bksh.al. Nëse i rezistuat të klikuarit të link-ut, mos kini merak - do t’ju tregoj mjaftueshëm në këtë shkrim, ndërsa ju që u kthyet pasi klikuat, mirëseerdhët: do të flasim për çfarë mungon tek ajo që sapo patë.
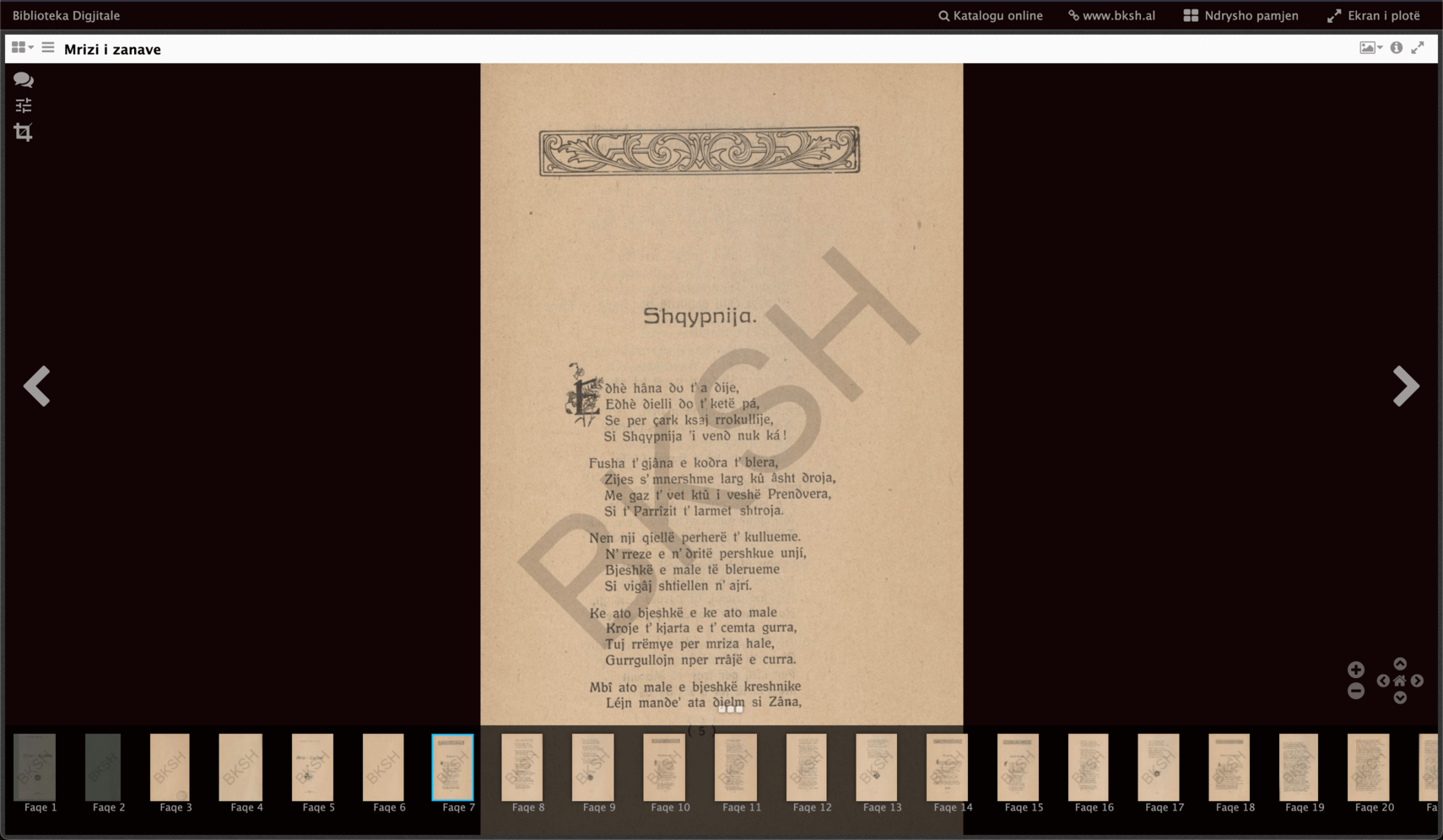
Si fillim, Biblioteka Kombëtare skanon faqet e veprave në katalog, dhe i ofron këto nëpërmjet një sistemi që quhet International Image Interoperability Framework (IIIF)[2], në shqip: Kuadri Ndërkombëtar i Ndërveprueshmerisë së Imazheve). IIIF e bën të mundur qe çdo imazh të shoqërohet nga metadata të dobishme, por për fat të keq ajo që do doja të kisha gjetur për Fletoret: tesktin e ketyre veprave, nuk e gjeta. Kjo është arsyeja pse së bashku me një grup të vogël vullnetaresh, po përpiqemi të kopjojmë veprën e Gjergj Fishtes: Mrizi i Zânavet nga versioni i skanuar (shiko Figuren 1), në tekst, që të mund të lexohet dhe ndahet lehtësisht. Këtë përpjekje mund ta ndiqni tek fletoret.com/fishta.
Përshpejtimi i kopjimit
Ajo që duam të ndërtojme, është një mjet qe të na ndihmojë të kopjojmë përmbajtjen e këtyre librave dixhital nga BKD sa më shpejt. Sfidat janë këto:
- Kopjo çdo faqe nga një libër si imazh.
- Për secilën, lexo dhe shkruaj tekstin në këtë imazh.
- Kopjo tekstin në një dokument të pastër.
- Edito dokumentin e paster që të jete i publikueshëm.
Sado të madhe ta kesh dëshirën si vullnetar, realiteti i të kopjuarit rresht
për rresht gegnishten e pastandartizuar me germa si: â, é, î, ý, …,
ta zbut vullnetin, sikur vetëm prej faktit që këto germa nuk di as si t’i
nxjerrësh nga tastiera.
Një lexues i kujdesshëm, do e ketë vënë re që ndoshta disa prej këtyre hapave mund të kombinohen, dhe një pjese më e madhe mund të automatizohen duke përdorur pak teknologji. Kjo është ajo që do bëjmë, Kohën që mbetet deri në fund të ketij shkrimi do ta shpenzojmë duke shpjeguar teknikisht dhe shkurtimisht, ndërtimin e ketyrë mjeteve modeste që e bejne këtë situatë jo të përkryer, pak më të tolerueshme. Rezultati i kësaj përpjekje është Kopjuesi: fletoret.com/ocr.
Nëse doni të ndihmoni, shikoni çfarë pjesësh mungojnë nga Mrizi i Zânavet tek Fletoret, dhe përdorni Kopjuesin për ta bërë gati për publikim, fillimisht duke e dërguar në Reddit: r/fletoret ose Twitter: @FletoretSQ.
Shënim teknik: Paragrafët që vijojnë përmbajnë disa detaje teknike mbi ndërtimin e Kopjuesit, dhe nuk është e nevojshme t’i lexoni, … përveçse, jeni kuriozë ose doni të mësoni si t’i përdorni këto mjete për vepra të tjera.
Fillimisht, duhet të ndajme problemin e të ndërtuarit të Kopjuesit në copa të vogla:
- Problemi 1: Shkarko të gjithë imazhet.
- Problemi 2: Konverto secilin imazh në tekst.
- Problemi 3: Shërbeji imazhet përbri tekstit të gjeneruar.
Problemi 1: Shkarko të gjithë imazhet.
Fillimisht, mësuam që sistemi që përdor BKD është IIIF,
dhe pas një kërkimi të shkurtër, siç pritej, mësojmë që ka edhe njerëz të tjerë me të njëjtin problem: Automatizimin e shkarkimit të imazheve nga servera IIIF.
Një prej këtyre projekteve është iiif_downloader nga Yale Digital Humanities
Lab [3].
Më poshtë është një shembull i shkurtër se si të shkarkojmë të gjithë
faqet e Mrizit të Zanave si imazhe. Gjithçka që duhet të dimë, është
adresa e asaj që në IIIF quhet Manifest i veprës. Këtë mund ta gjejmë
tek shenja e informacionit i tek BKD.
from iiif_downloader import Manifest
MANIFEST_URL_MRIZI_I_ZANAVE ='https://bibliotekadigjitale.bksh.al/iiif/Manifester/IIIF/libra!HASHae57.dir'
def download_images(manifest_url):
Manifest(url=MANIFEST_URL_MRIZI_I_ZANAVE).save_images()
Kjo krijon një direktori që quhet iiif-downloads, në të cilen
ndodhet një nëndirektori: images, ku gjejmë të gjithë imazhet.
Problemi 2: Konverto secilin imazh në tekst.
Edhe ky është një problem i mirëstudiuar, për të cilin mund të kërkoni më shumë duke shkruar Optical Character Recognition (OCR). Në vija të trasha, sa më i mirë skanimi, sa më e thjështë tipografia dhe sa më popullore gjuha aq më cilësor do të jetë konvertimi i përmbajtjes së imazhit në tekst. Pra, në fund të ketij proçesi duhet që një editor gjithsesi ta kontrollojë tekstin, por ky hall është minimal krahasuar me të kopjuarit manual të kësaj përmbajtje.
Ka shumë projekte që mund të përdoren për konvertimin e imazheve në teskt.
Nëse keni shumë pak imazhe, mund ta bëni dhe online. Për këtë shembull do të
përdorim ocrmac [4], zgjedhje shumë e mirë nëse përdorni një kompjuter Apple
, por parimi është i njëjtë për çdo projekt tjetër, e.g.: tesseract [5].
Nga Problemi 1, kemi të gjithë imazhet në iiif-downloads/images. Le
të marrim një imazh specifikisht për të pare si do të funksionojë.
Marrim faqen 7: iiif-downloads/images/libra1!HASHae57.dir!page7.png

Tani, shkruajmë një program të vogel për të parë çfarë mund të nxjerrim nga imazhi:
from ocrmac import ocrmac
IMG_URL_PATH = "./iiif-downloads/images/libra1!HASHae57.dir!page7.png"
annotations = ocrmac.OCR(IMG_URL_PATH).recognize()
for (text, confidence) in annotations:
print(text)
dhe rezultati është:
Shaypnija.
ôhè hâna do t' a dije,
Eohè dielli do t' kete pá,
Se per cark ksaj rrokullije,
Si Shaypnija 'i veno nuk ká !
Fusha t' gjna e kodra t' blera,
Zijes s'mnershme larg kû âsht droja,
Me gaz t' vet ktû i veshe Prenovera,
Si t' Parrizit t' larmet shtroja.
Nen nji gielle perhere t kullueme.
N' rreze e n'drite pershkue unjí,
Bjeshke e male të blerueme
Si vigâj shtiellen n' ajrí.
Ke ato bjeshke e ke ato male
Kroje t' kjarta e t' cemta gurra,
Tuj rremye per mriza hale,
Gurrgulloin per rrâje e curra.
Mbi ato male e bjeshke kreshnike
Léin mande' ata djelm si Zâna,
( 5 )
Siç duket, ka goxha gabime, ku dallohet ngatërrimi i d, q, j, ç,
por nga ana tjetër: është shumë më e lehte të korrigjosh gabimet, se sa ta
kopjosh nga e para.
Problemi 3: Shërbeji imazhet përbri tekstit të gjeneruar.
Problemet thelbësore janë zgjidhur. Në këtë hap, do të krijojmë një file
mrizi_i_zanavet.json, ku do të ruajmë çdo imazh dhe tekstin e nxjerrë
prej tij, sipas numrit të faqes. Meqënëse imazhet janë të mëdha, dhe ne
nuk duam të paguajmë koston e ruajtjes dhe shërbyerit të tyre, do të përdorim
URL-në e imazheve që shërben Biblioteka Kombëtare.
Struktura përfundimtare do të jete diçka e tillë:
[
# Faqja 1
[
# URL e imazhit për faqen 1
"https://bibliotekadigjitale.bksh.al/iiif/Scaler/IIIF/libra1!HASHae57.dir!page1.png/full/,1500/0/default",
# annotations
[
[
rreshti_n,
confidenca
]
...
]
]
... Faqet e tjera
]
Ka disa mënyra për ta strukturuar këtë informacion, kjo është vetëm një prej tyre. Tani le të shkruajmë një program të vogël që nxjerr tekstin për të gjithë imazhet, dhe i ruan përbri njëri-tjetrit:
import os
import json
from ocrmac import ocrmac
from rich.progress import track
IMAGE_BASE_URL = "https://bibliotekadigjitale.bksh.al/iiif/Scaler/IIIF/"
def get_image_url(img_name):
"""Funksion qe na mundeson të ndertojme URL-ne e imazhit tek
Biblioteka Kombetare nga emri i file qe kemi shkarkuar.
Shembull:
https://bibliotekadigjitale.bksh.al/iiif/Scaler/IIIF/libra1!HASHae57.dir!page7/full/,1500/0/default
"""
return f"{IMAGE_BASE_URL}{img_name}/full/,1500/0/default"
def annotate_collection():,
with open("mrizi_i_zanave.json", "w") as f:
output = []
image_dir = "./iiif-downloads/images/"
# Rendisim sipas nr të faqes
sorted_img_names = sorted(
os.listdir(image_dir),
key=lambda x: int(x.split("!page")[1].removesuffix(".png"))
)
for i in track(range(len(sorted_img_names)), description="Processing..."):
img_name = sorted_img_names[i]
annotations = ocrmac.OCR(f"{image_dir}/{img_name}").recognize()
text = [[text, confidence] for text, confidence, _ in annotations]
output.append([get_image_url(img_name), text])
f.write(json.dumps(output, indent=2))
Kaq ishte. Tani kemi gjithçka që na duhet për të ndërtuar atë që shikoni tek fletoret.com/ocr. Pjesa tjetër i lihet detyrë lexuesit :)
Referenca:
Sipas ligjit: Nr. 35/2016: Për të drejtat e autorit dhe të drejtat e tjera të lidhura me to, veprat e të gjithë shkrimtarëve që kanë vdekur para 70 vitesh, janë pasuri publike (në domain-in publik). - kultura.gov.al ↩︎
International Image Interoperability Framework - https://iiif.io/ ↩︎
ocrmac - A python wrapper to extract text from images on a mac system. Uses the vision framework from Apple. - GitHub ↩︎